

昨晩から googleサーチコンソール を確認しています。
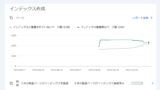
「ページがインデックスに登録されなかった理由」ってのを調べるのです。
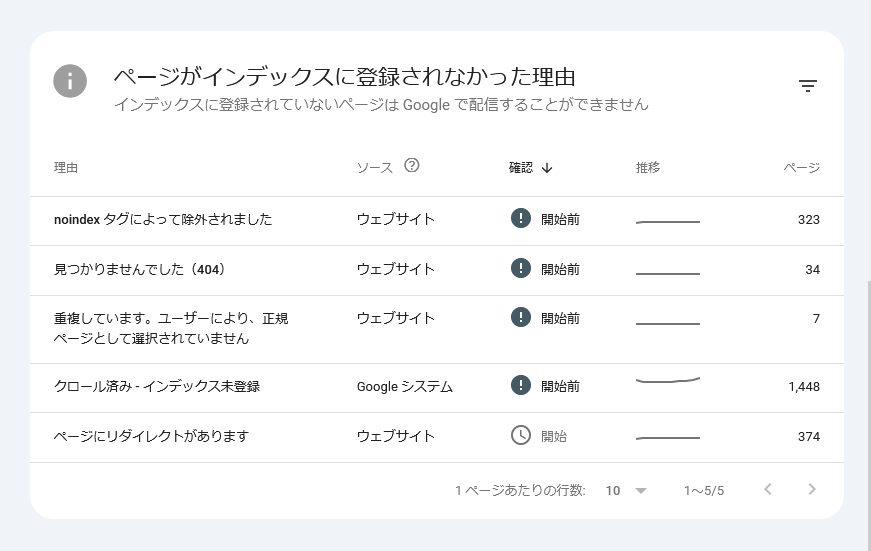
「見つかりませんでした(404)」は物理的に記事内容を確認したりして解決です。
「重複しています。ユーザーにより、正規ページとして選択されていません」
「重複しています。ユーザーにより、正規ページとして選択されていません」ってのは…
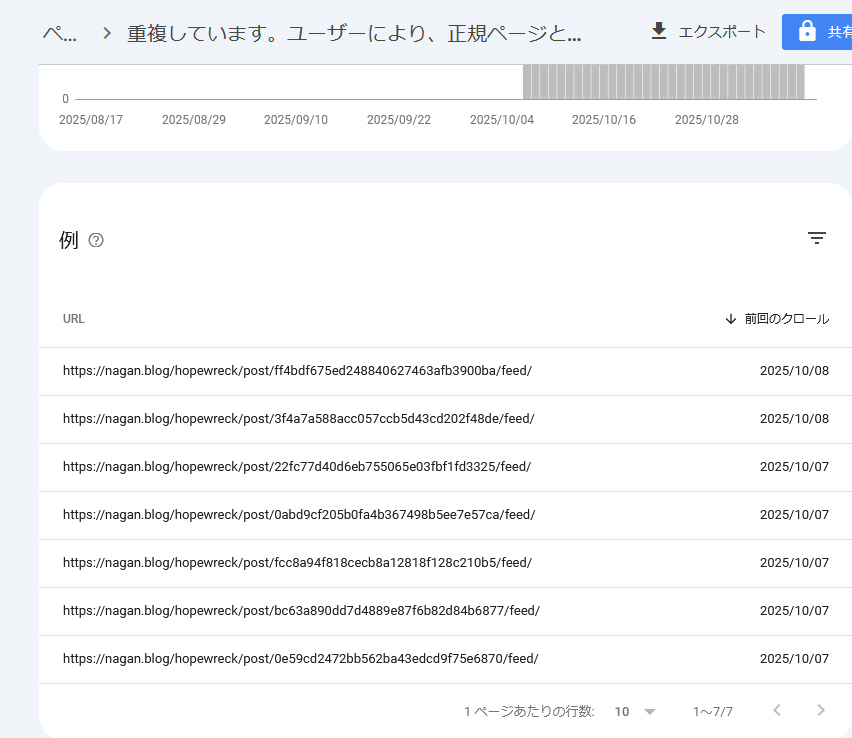
ブログ記事URLの後ろに /feed/ ってのが追加されているものです。
feed ってホームページの更新情報をXMLで云々ってやつだったと記憶しているのですが….
ネットをググると…ほら私のうっすらとした遠い記憶は合っているみたい。

そんなのはもちろんインデックス登録不要なのでこのエラーでいいよね。

つまり、そのまま放置の助にしておこう。
「noindex タグによって除外されました」
次は、「noindex タグによって除外されました」です。
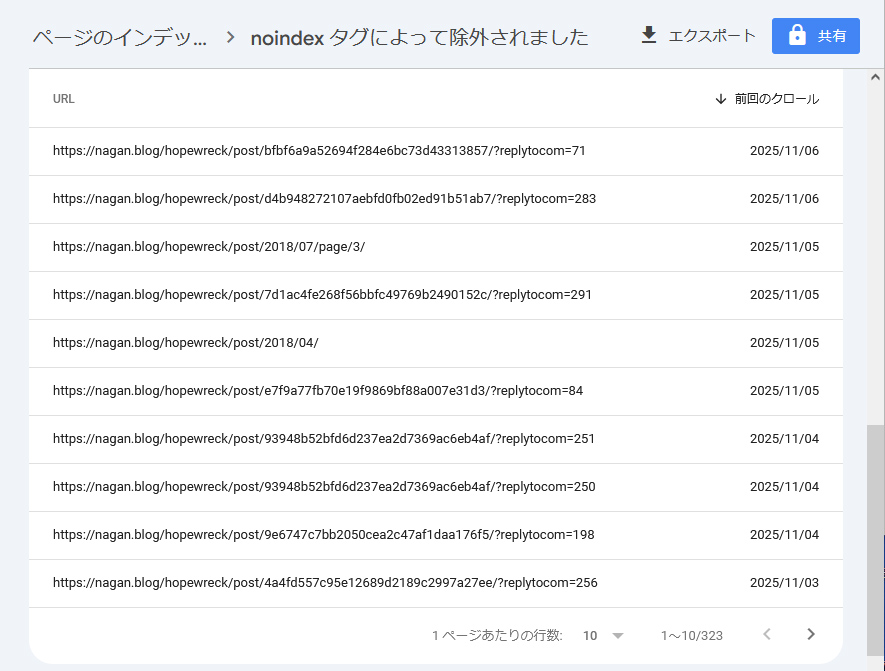
「replytocom」ってのがキーワードだね。
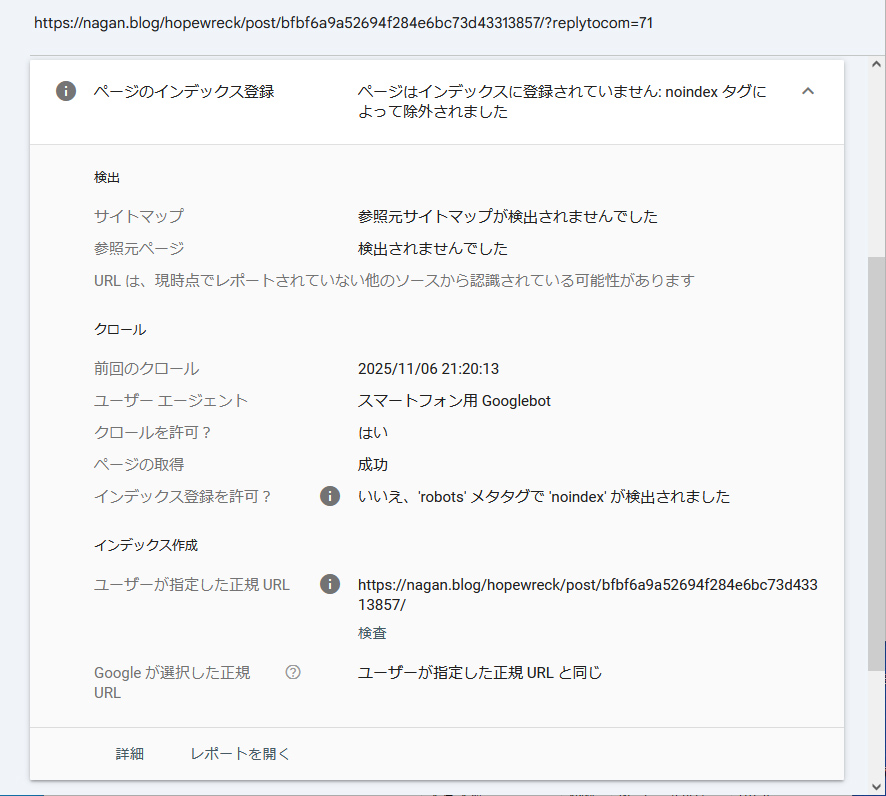
ネットをググって、「ブログのコメントに返信するたびに生成されるURLパラメータ」と知る。

試しに、次のURLをブラウザで確認する。
https://nagan.blog/hopewreck/post/bfbf6a9a52694f284e6bc73d43313857/?replytocom=71たしかに、コメント毎にURLが生成されているんだわ。
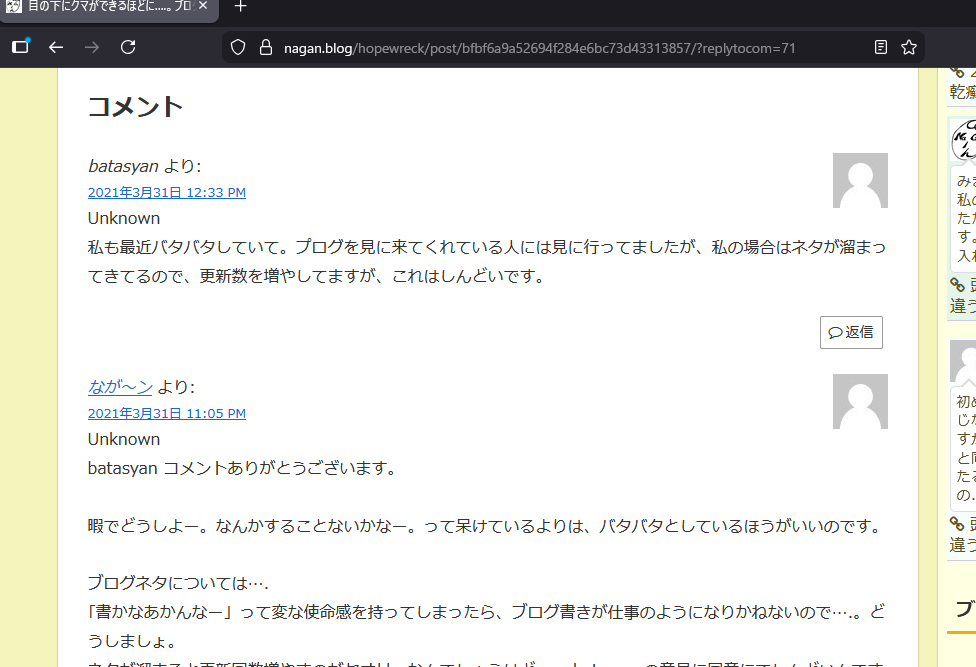
コメントだから検索エンジンにindex登録されないように「noindex」指定をwordpressがしている。って、wordpressってそんなこともしているのかーい。
で、この「replytocom」がURLパラメーターとして、googleサーチが除外するようにすればいいわけで…
調べたら2方法あり。
一つは先のページで記されている Google Search Consoleのクロール設定 で指定する。
もう一つは、robots.txt に追記するもの。私がここに書くまでもなくよそ様が親切な情報ページを書いている。

で、私はどちらを採用するのかというと….
なるだけブログの設定とか、サーバー内のファイルを弄るというのはしたくないわけよ。
そういうところを触ると、後々のメンテをするときにどこをどうしたっけ?となるわけで….
「replytocom」についてはブログ記事に関する問題ではないので、googleサーチコンソール 側の設定でするのがスムーズではないかと…
Google Search Consoleのクロール設定 をしようとしたのですが、googleサーチコンソール のバージョン違いなのだろう、メニュー構成が違うよ。
メニューをいろいろと押して探すのだけど、Google Search Console のクロール、URLパラメーターに関する設定画面にたどりつけずです。
きっと、オイラはバカなんでしょう。みつかりません。わかりません。となりました。
AI先生に尋ねてみたら、Google Search Console の「クロール」>「URLパラメータ」は古いバージョンのもので、現行バージョンでは廃止されているという。
robots.txt を修正
いいもん、robots.txt 弄るもん。
自分のブログURLの robots.txt に、
Disallow: /?replytocom=
を追記するだけです。
なのですが、自分のサーバに robots.txt は存在しないのに、ブラウザーでアクセスすると robots.txt が表示されるどうなっとんねん?
またAI先生にお尋ねすると、 robots.txt が存在しないときはwordpressが自動返答で引き渡しているという。
だから、wordpressが自動生成している robots.txt をテキストファイルに起こしたうえで、Disallow: /?replytocom= を追記して、新規 robots.txt を作成してFTPでアップロードとなりました。
次は、Google Search Console の設定-クロールのrobots.txtをクリックして
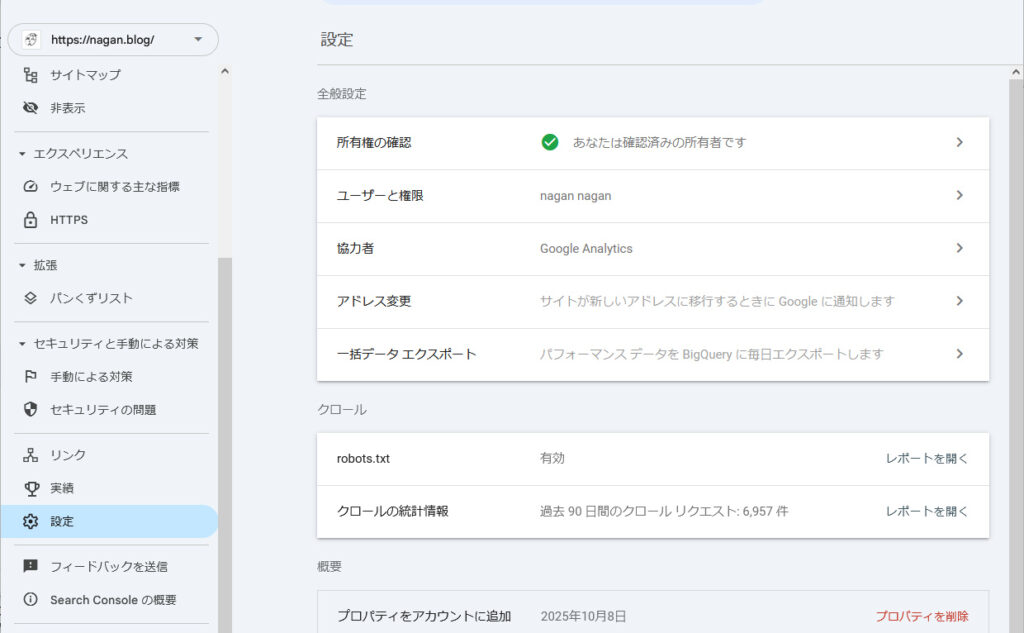
再クロールをリクエストして、あとは寝て待つだけでいいよね。
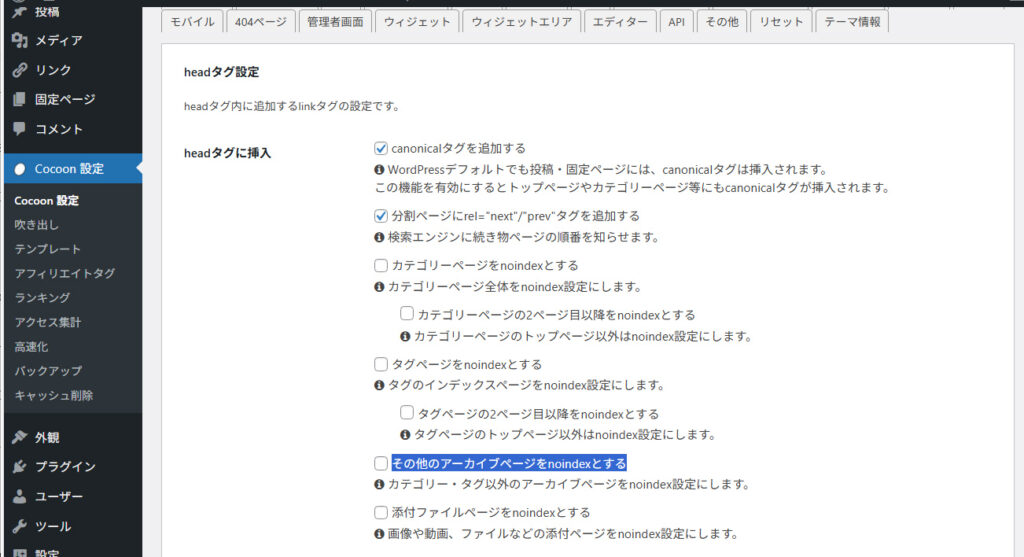
「cocoon設定」>「seo」>「headタグに挿入」
あとは…
アーカイブページ https://nagan.blog/hopewreck/post/2018/07/page/3/ とかが引っかかっているのは…
wordpress、「cocoon設定」>「seo」>「headタグに挿入」 のところで
「その他のアーカイブページをnoindexとする」にチェックがはいっていたからではないかと思う。
headタグに挿入の noindex に関するチェックを全部外しておいた。
次の課題、「クロール済み – インデックス未登録」
次は….
「クロール済み – インデックス未登録」ってやつ。件数が多いよね。
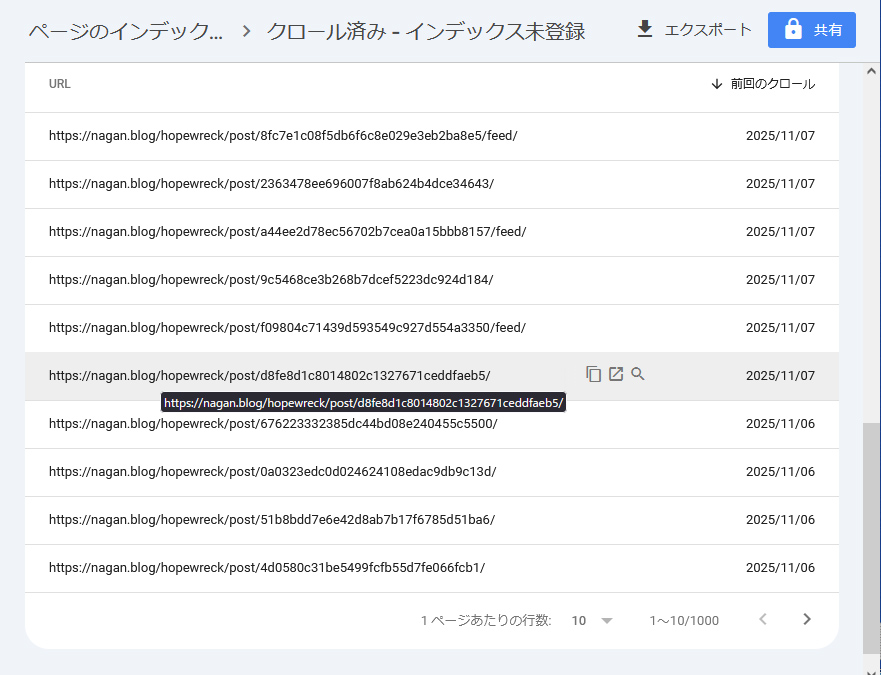
/feed/のやつは先に設定したやつで対策できているはずだから置いといて…
とりあえず、指摘されているURL記事を確認してみる。
https://nagan.blog/hopewreck/post/d8fe8d1c8014802c1327671ceddfaeb5/の欄にある虫眼鏡アイコンクリックして…
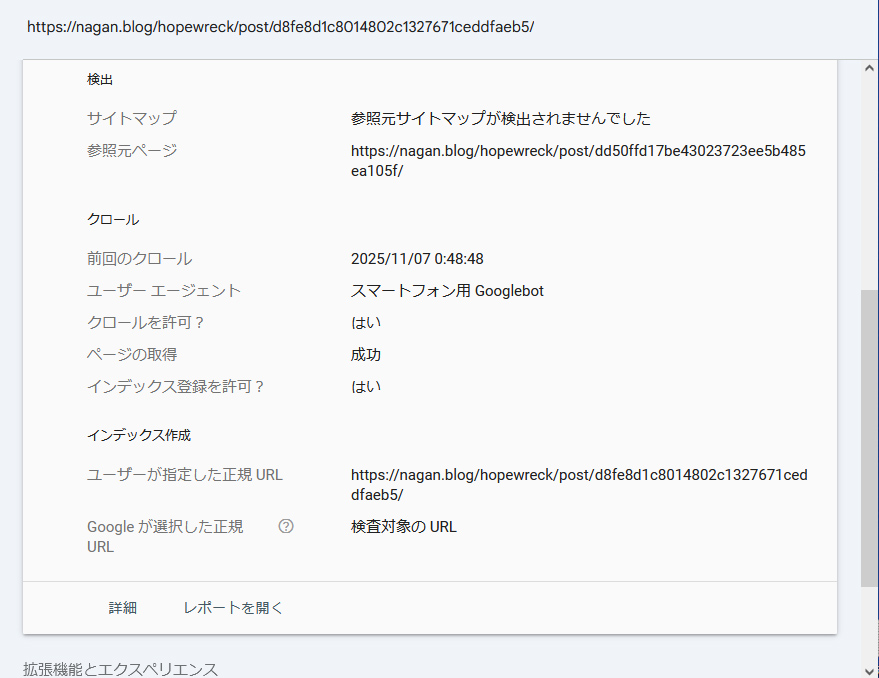
えーと、このページに出てくる二つのURL
参照元ページ
https://nagan.blog/hopewreck/post/dd50ffd17be43023723ee5b485ea105f/ユーザーが指定した正規 URL
https://nagan.blog/hopewreck/post/d8fe8d1c8014802c1327671ceddfaeb5/は、どちらも存在しているんよね。
となると….
参照元サイトマップが検出されませんでしたのワードが問題ってことだ。
サイトマップ・・・。それって何?
ってのを今晩は追及してみよう。
ここまでで、自分の記録として作業した内容をそのまま書き込んで置いた。
はい、ブログ初診者がするような初歩でしくじっているってことですな。
頑張りませう。
このブログは XServer を使って運営しています。激貧を自負する私が、コストパフォーマンスで選んだサーバーだよ。
それに、エックスサーバーが「Cocoon」の開発業務を全面的にサポートし、開発や公式サイトの運営はわいひらさんとエックスサーバーの開発メンバーという構成だしね。
興味がある人向けにcocoonへのリンクを置いておくね。下のリンク経由で契約したらお得になるはず。

XServer契約者のお友達紹介プログラムに「なが~ン」は参加しています。ここのリンクからXServerへ行って契約したら約20%割引されるよ。
リンクを踏むと「お友達紹介プログラムが適用されています」といった類の表示がされるのを確認してね。
「なが~ン」がブログでアフィリエイトを始めたときに順番に登録申し込みしたアフェリエイトサイトを紹介するね。(2026年3月7日時点)
車関連(タイヤ屋、電灯屋、車検見積もり)といった広告案件があるんよね。車関係は私のジャンルだよ。
審査が通りやすいと噂されている A8.net。
ブログでアフィリといえば定番だね。
![]()
ブログアフィリで、Amazon、楽天市場、の物販を扱いたいなら もしもアフィリエイト
ブログアフィリエイトで Yahoo!ショッピング を貼りたいなら
バリューコマース

以上が、私が登録しているアフィリです。
えっ?たったの4件だけ?と、アフィリをされている先輩方からは弄られそうですね。
でも、私の自由時間ではこの4件だけでも手一杯なんです。
自分の治療が優先、ブログは2の次なのよね。でも、激貧家庭は少しでも金欲しいなのよ(笑)
コメント